Сравнение с Excel¶
Многие потенциальные пользователи pandas имеют некоторое представление о программах для работы с электронными таблицами, такими как Excel. На этой странице приведены примеры того, как выполняются различные операции с электронными таблицами с помощью pandas. На этой странице используется терминология Excel и ссылки на документацию Excel, но многое похожим образом делается в Google Таблицах, LibreOffice Calc, Apple Numbers и в другом программном обеспечении для работы с электронными таблицами, совместимом с Excel.
Если вы новичок в pandas, вы можете сначала прочитать 10 Minutes to pandas, чтобы ознакомиться с библиотекой.
Как обычно, импортируем pandas и NumPy следующим образом:
In [1]: import pandas as pd
In [2]: import numpy as np
Структуры данных¶
Перевод общей терминологии¶
pandas |
Excel |
|---|---|
DataFrame |
лист |
Series |
столбец |
Index |
заголовки строк |
строка |
строка |
NaN |
пустая ячейка |
DataFrame¶
DataFrame в pandas аналогичен листу в Excel. В то время как книга Excel может содержать несколько листов, DataFrame в pandas существуют независимо друг от друга.
Series¶
Series — это структура данных, представляющая один столбец DataFrame. Работа с Series аналогична работе со столбцом электронной таблицы.
Index¶
У каждого DataFrame и Series есть Index, который является меткой для строк данных. В pandas, если индекс не указан, по умолчанию используется RangeIndex (первая строка = 0, вторая строка = 1 и так далее), аналогично заголовкам или номерам строк в электронных таблицах.
В pandas индекс можно установить на одно или несколько уникальных значений, что похоже на наличие столбца, который используется в качестве идентификатора строки на листе. В отличие от большинства электронных таблиц, эти значения Index могут фактически использоваться для ссылки на строки. (Обратите внимание, это можно сделать в Excel со структурированными ссылками.) Например, в электронных таблицах вы бы ссылались на первую строку как A1:Z1, а в pandas бы использовали populations.loc['Chicago'].
Значения индекса постоянны, поэтому, если вы измените порядок строк в DataFrame, метка для конкретной строки не изменится.
См. документацию по индексированию, чтобы узнать больше о том, как эффективно использовать Index.
Копии и операции на месте¶
Большинство операций pandas возвращают копии Series и DataFrame. Чтобы зафиксировать изменения, вам нужно либо назначить новую переменную:
sorted_df = df.sort_values("col1")
Либо перезаписать исходный объект:
df = df.sort_values("col1")
Примечание
Вы можете столкнуться с аргументом inplace=True, доступным для некоторых методов:
df.sort_values("col1", inplace=True)
Ввод и вывод данных¶
Построение DataFrame из значений¶
В электронной таблице значения можно вводить непосредственно в ячейки.
DataFrame в pandas можно создать разными способами, но для небольшого количества значений часто бывает удобно указать его как словарь Python, где ключи — это имена столбцов, а значения — это данные.
In [3]: df = pd.DataFrame({"x": [1, 3, 5], "y": [2, 4, 6]})
In [4]: df
Out[4]:
x y
0 1 2
1 3 4
2 5 6
Чтение данных из внешних источников¶
И Excel, и pandas могут импортировать данные из разных источников в разных форматах.
CSV¶
Давайте загрузим из тестов pandas и отобразим набор данных tips в формате CSV. В Excel вам нужно загрузить, а затем открыть файл CSV. В pandas вы передаете URL-адрес или локальный путь файла CSV в read_csv():
In [5]: url = (
...: "https://raw.github.com/pandas-dev"
...: "/pandas/main/pandas/tests/io/data/csv/tips.csv"
...: )
...:
In [6]: tips = pd.read_csv(url)
In [7]: tips
Out[7]:
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
.. ... ... ... ... ... ... ...
239 29.03 5.92 Male No Sat Dinner 3
240 27.18 2.00 Female Yes Sat Dinner 2
241 22.67 2.00 Male Yes Sat Dinner 2
242 17.82 1.75 Male No Sat Dinner 2
243 18.78 3.00 Female No Thur Dinner 2
[244 rows x 7 columns]
Подобно Мастеру импорта текста Excel, read_csv в pandas принимает ряд параметров, которые позволяют указать, как нужно проанализировать данные. Например, если бы данные были разделены табуляцией и не имели имен столбцов, команда pandas была бы такой:
tips = pd.read_csv("tips.csv", sep="\t", header=None)
# alternatively, read_table is an alias to read_csv with tab delimiter
tips = pd.read_table("tips.csv", header=None)
Файлы Excel¶
Excel открывает файлы различных форматов Excel двойным щелчком мыши или через меню Открыть. В pandas используются специальные методы для чтения и записи файлов Excel.
Давайте сначала создадим новый файл Excel на основе данных tips из приведенного выше примера:
tips.to_excel("./tips.xlsx")
Если вы хотите впоследствии получить доступ к данным в файле tips.xlsx, вы можете прочитать его так:
tips_df = pd.read_excel("./tips.xlsx", index_col=0)
Вы только что прочитали файл Excel с помощью pandas!
Ограничение вывода¶
Программы для работы с электронными таблицами отображают данные, которые помещаются на экране, а затем позволяют прокручивать их, так что на самом деле нет необходимости ограничивать вывод. В pandas приходится подумать о том, как отображаются DataFrame.
По умолчанию pandas обрезает вывод больших DataFrame, чтобы показать первую и последнюю строки. Это можно переопределить, изменив параметры pandas или используя DataFrame.head() или DataFrame.tail().
In [8]: tips.head(5)
Out[8]:
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
Экспорт данных¶
По умолчанию программное обеспечение для работы с электронными таблицами сохраняет файлы в соответствующем формате (.xlsx, .ods и т. д.). Однако вы можете сохранить файл в другом формате.
pandas может создавать файлы Excel, CSV и файлы других форматов.
Операции с данными¶
Операции над столбцами¶
В электронных таблицах формулы часто создаются в отдельных ячейках. а затем перетаскиваются в другие ячейки, чтобы применить аналогичные операции ко всем ячейкам в столбце. В pandas вы можете напрямую выполнять операции над целыми столбцами.
pandas обеспечивает векторизованные операции, указывая отдельные Series в DataFrame. Таким же образом можно назначить новые столбцы. Метод DataFrame.drop() удаляет столбец из DataFrame.
In [9]: tips["total_bill"] = tips["total_bill"] - 2
In [10]: tips["new_bill"] = tips["total_bill"] / 2
In [11]: tips
Out[11]:
total_bill tip sex smoker day time size new_bill
0 14.99 1.01 Female No Sun Dinner 2 7.495
1 8.34 1.66 Male No Sun Dinner 3 4.170
2 19.01 3.50 Male No Sun Dinner 3 9.505
3 21.68 3.31 Male No Sun Dinner 2 10.840
4 22.59 3.61 Female No Sun Dinner 4 11.295
.. ... ... ... ... ... ... ... ...
239 27.03 5.92 Male No Sat Dinner 3 13.515
240 25.18 2.00 Female Yes Sat Dinner 2 12.590
241 20.67 2.00 Male Yes Sat Dinner 2 10.335
242 15.82 1.75 Male No Sat Dinner 2 7.910
243 16.78 3.00 Female No Thur Dinner 2 8.390
[244 rows x 8 columns]
In [12]: tips = tips.drop("new_bill", axis=1)
Обратите внимание, что нам не пришлось выполнять вычитание по ячейкам — pandas сделал это за нас. См. как создать новые столбцы, производные от существующих столбцов.
Фильтрация¶
В Excel фильтрация осуществляется через графическое меню.
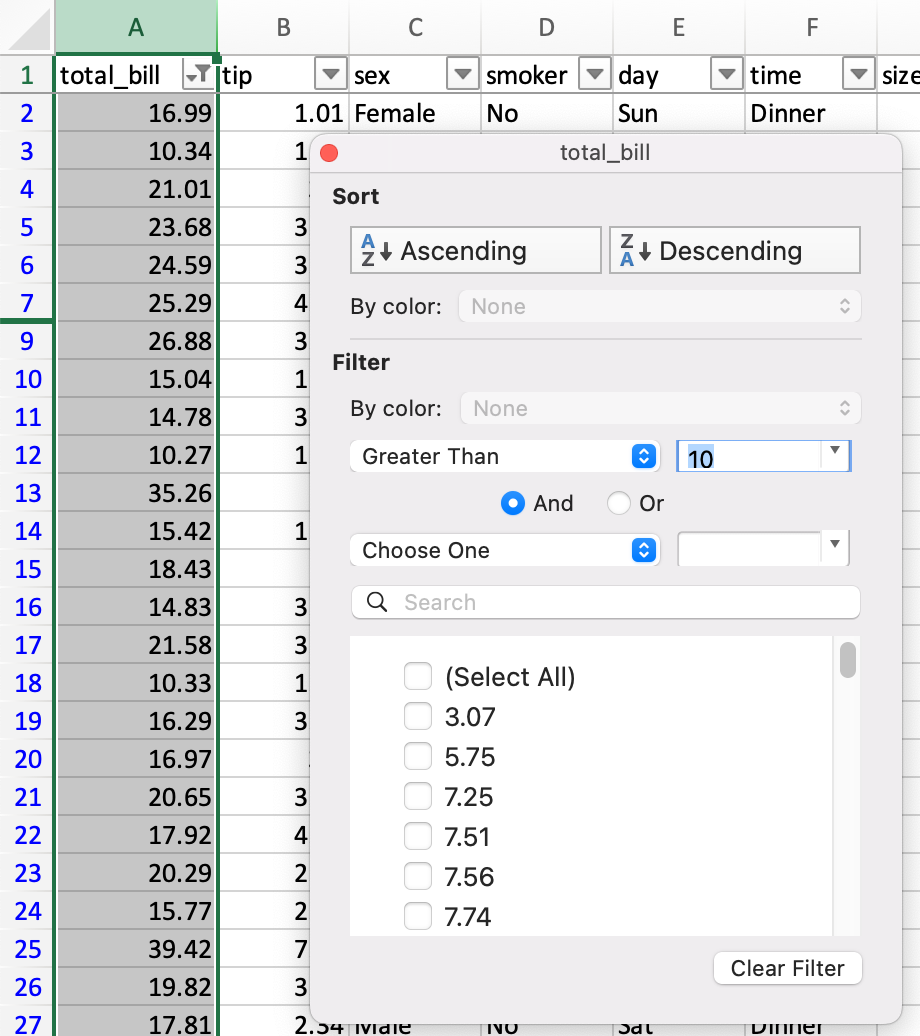
DataFrame можно фильтровать несколькими способами; наиболее интуитивным из них является использование логического индексирования.
In [13]: tips[tips["total_bill"] > 10]
Out[13]:
total_bill tip sex smoker day time size
0 14.99 1.01 Female No Sun Dinner 2
2 19.01 3.50 Male No Sun Dinner 3
3 21.68 3.31 Male No Sun Dinner 2
4 22.59 3.61 Female No Sun Dinner 4
5 23.29 4.71 Male No Sun Dinner 4
.. ... ... ... ... ... ... ...
239 27.03 5.92 Male No Sat Dinner 3
240 25.18 2.00 Female Yes Sat Dinner 2
241 20.67 2.00 Male Yes Sat Dinner 2
242 15.82 1.75 Male No Sat Dinner 2
243 16.78 3.00 Female No Thur Dinner 2
[204 rows x 7 columns]
Вышеприведенный оператор просто передает Series объектов True и False в DataFrame, возвращая все строки с True.
In [14]: is_dinner = tips["time"] == "Dinner"
In [15]: is_dinner
Out[15]:
0 True
1 True
2 True
3 True
4 True
...
239 True
240 True
241 True
242 True
243 True
Name: time, Length: 244, dtype: bool
In [16]: is_dinner.value_counts()
Out[16]:
True 176
False 68
Name: time, dtype: int64
In [17]: tips[is_dinner]
Out[17]:
total_bill tip sex smoker day time size
0 14.99 1.01 Female No Sun Dinner 2
1 8.34 1.66 Male No Sun Dinner 3
2 19.01 3.50 Male No Sun Dinner 3
3 21.68 3.31 Male No Sun Dinner 2
4 22.59 3.61 Female No Sun Dinner 4
.. ... ... ... ... ... ... ...
239 27.03 5.92 Male No Sat Dinner 3
240 25.18 2.00 Female Yes Sat Dinner 2
241 20.67 2.00 Male Yes Sat Dinner 2
242 15.82 1.75 Male No Sat Dinner 2
243 16.78 3.00 Female No Thur Dinner 2
[176 rows x 7 columns]
Логика if/then¶
Допустим, мы хотим создать столбец bucket со значениями low и high, в зависимости от того, меньше или больше 10 долларов значение в total_bill.
В электронных таблицах логическое сравнение можно выполнить с помощью условных формул. Мы бы использовали формулу =IF(A2 < 10, "low", "high"), перетащив ее во все ячейки в новом столбце bucket.
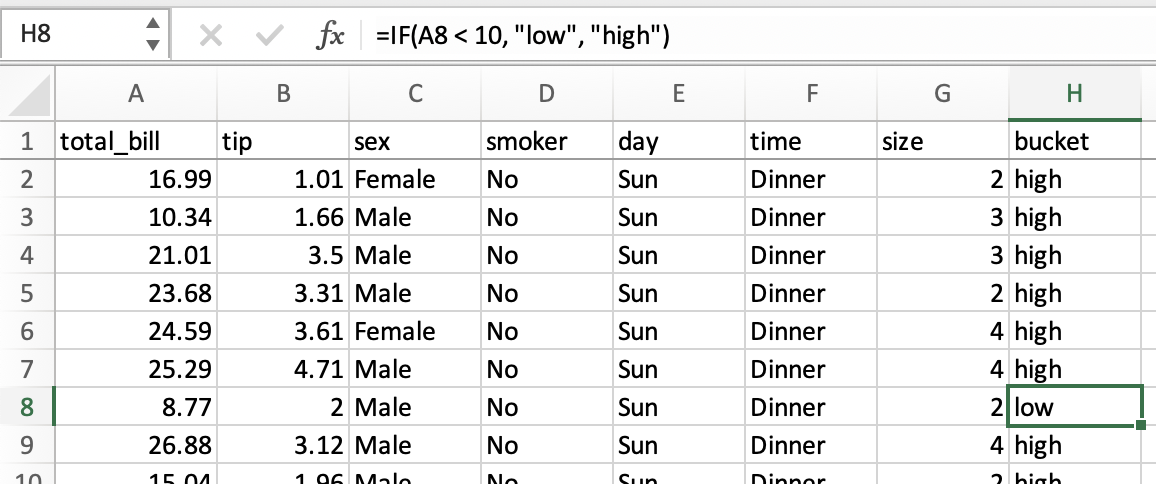
Ту же операцию в pandas можно выполнить с использованием метода where из numpy.
In [18]: tips["bucket"] = np.where(tips["total_bill"] < 10, "low", "high")
In [19]: tips
Out[19]:
total_bill tip sex smoker day time size bucket
0 14.99 1.01 Female No Sun Dinner 2 high
1 8.34 1.66 Male No Sun Dinner 3 low
2 19.01 3.50 Male No Sun Dinner 3 high
3 21.68 3.31 Male No Sun Dinner 2 high
4 22.59 3.61 Female No Sun Dinner 4 high
.. ... ... ... ... ... ... ... ...
239 27.03 5.92 Male No Sat Dinner 3 high
240 25.18 2.00 Female Yes Sat Dinner 2 high
241 20.67 2.00 Male Yes Sat Dinner 2 high
242 15.82 1.75 Male No Sat Dinner 2 high
243 16.78 3.00 Female No Thur Dinner 2 high
[244 rows x 8 columns]
Функциональность даты¶
В этом разделе будут упоминаться «даты», но метки времени обрабатываются аналогичным образом.
Функционал даты можно разделить на две части: синтаксический анализ и вывод. В электронных таблицах значения даты обычно анализируются автоматически, хотя существует функция DATEVALUE. В pandas вам нужно явно преобразовать обычный текст в объекты даты и времени, либо при чтении из CSV, либо в DataFrame.
После анализа электронные таблицы отображают даты в формате по умолчанию, хотя формат можно изменить. В pandas при вычислениях над датами их обычно хранят как объекты datetime. Вывод частей дат (например, года) осуществляется в электронных таблицах с помощью функций даты, а в pandas с помощью свойств datetime.
Учитывая date1 и date2 в столбцах A и B электронной таблицы, у вас могут быть следующие формулы:
столбец |
формула |
|---|---|
|
|
|
|
|
|
|
|
Эквивалентные операции pandas показаны ниже.
In [20]: tips["date1"] = pd.Timestamp("2013-01-15")
In [21]: tips["date2"] = pd.Timestamp("2015-02-15")
In [22]: tips["date1_year"] = tips["date1"].dt.year
In [23]: tips["date2_month"] = tips["date2"].dt.month
In [24]: tips["date1_next"] = tips["date1"] + pd.offsets.MonthBegin()
In [25]: tips["months_between"] = tips["date2"].dt.to_period("M") - tips[
....: "date1"
....: ].dt.to_period("M")
....:
In [26]: tips[
....: ["date1", "date2", "date1_year", "date2_month", "date1_next", "months_between"]
....: ]
....:
Out[26]:
date1 date2 date1_year date2_month date1_next months_between
0 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds>
1 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds>
2 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds>
3 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds>
4 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds>
.. ... ... ... ... ... ...
239 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds>
240 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds>
241 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds>
242 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds>
243 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds>
[244 rows x 6 columns]
См. более подробную информацию в разделе Time series / date functionality.
Выбор столбцов¶
В электронных таблицах вы можете выбрать нужные столбцы:
Ссылка на диапазон с одного листа на другой
Поскольку столбцы электронной таблицы обычно именуются в строке заголовка, переименование столбца — это просто изменение текста в заголовочной ячейке.
Аналогичные операции в pandas продемонстрированы ниже.
Сохранить определенные столбцы¶
In [27]: tips[["sex", "total_bill", "tip"]]
Out[27]:
sex total_bill tip
0 Female 14.99 1.01
1 Male 8.34 1.66
2 Male 19.01 3.50
3 Male 21.68 3.31
4 Female 22.59 3.61
.. ... ... ...
239 Male 27.03 5.92
240 Female 25.18 2.00
241 Male 20.67 2.00
242 Male 15.82 1.75
243 Female 16.78 3.00
[244 rows x 3 columns]
Удалить столбец¶
In [28]: tips.drop("sex", axis=1)
Out[28]:
total_bill tip smoker day time size
0 14.99 1.01 No Sun Dinner 2
1 8.34 1.66 No Sun Dinner 3
2 19.01 3.50 No Sun Dinner 3
3 21.68 3.31 No Sun Dinner 2
4 22.59 3.61 No Sun Dinner 4
.. ... ... ... ... ... ...
239 27.03 5.92 No Sat Dinner 3
240 25.18 2.00 Yes Sat Dinner 2
241 20.67 2.00 Yes Sat Dinner 2
242 15.82 1.75 No Sat Dinner 2
243 16.78 3.00 No Thur Dinner 2
[244 rows x 6 columns]
Переименовать столбец¶
In [29]: tips.rename(columns={"total_bill": "total_bill_2"})
Out[29]:
total_bill_2 tip sex smoker day time size
0 14.99 1.01 Female No Sun Dinner 2
1 8.34 1.66 Male No Sun Dinner 3
2 19.01 3.50 Male No Sun Dinner 3
3 21.68 3.31 Male No Sun Dinner 2
4 22.59 3.61 Female No Sun Dinner 4
.. ... ... ... ... ... ... ...
239 27.03 5.92 Male No Sat Dinner 3
240 25.18 2.00 Female Yes Sat Dinner 2
241 20.67 2.00 Male Yes Sat Dinner 2
242 15.82 1.75 Male No Sat Dinner 2
243 16.78 3.00 Female No Thur Dinner 2
[244 rows x 7 columns]
Сортировка по значениям¶
Сортировка в электронных таблицах осуществляется с помощью диалогового окна сортировки.
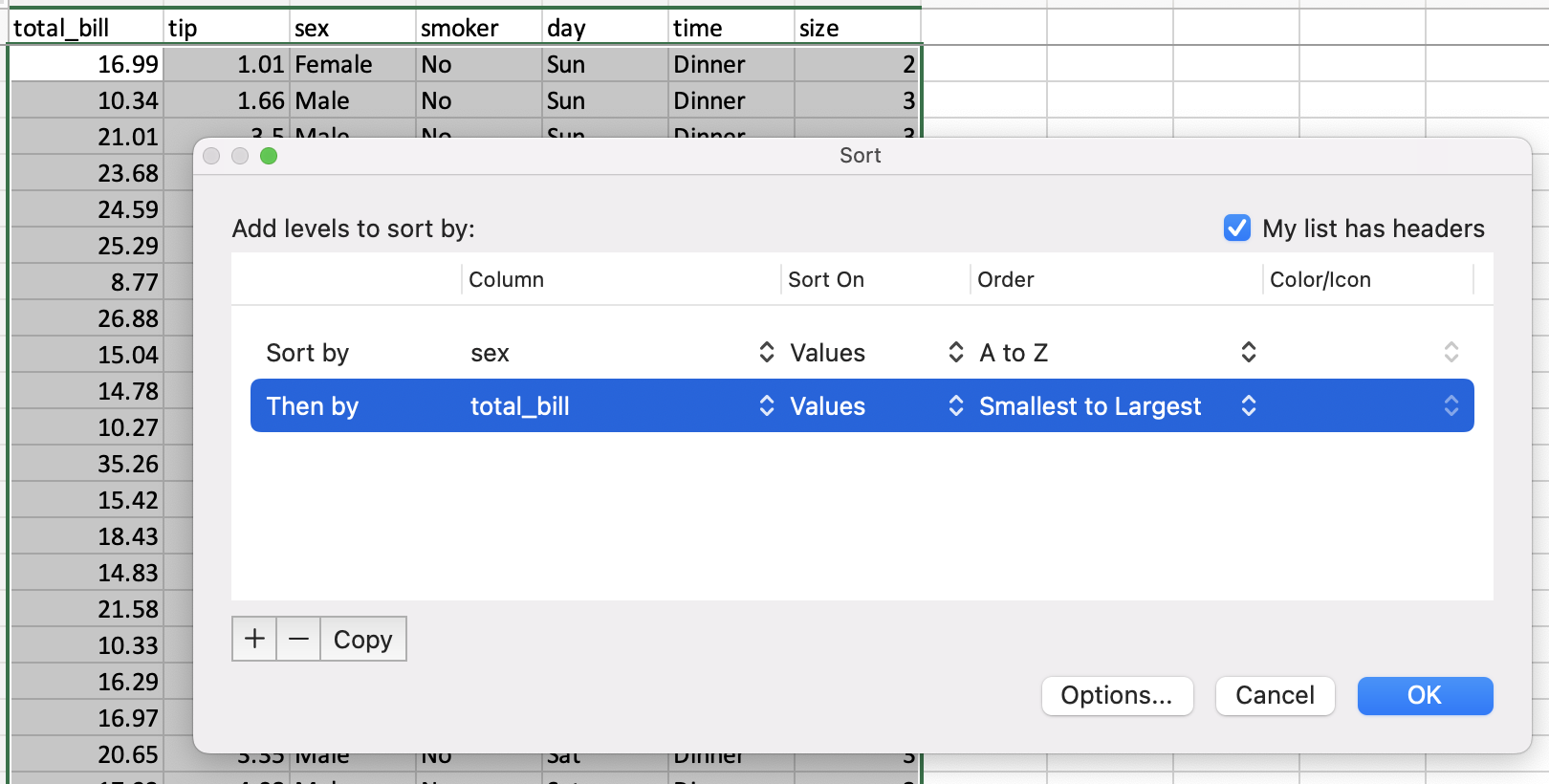
У pandas есть метод DataFrame.sort_values(), который принимает список столбцов для сортировки.
In [30]: tips = tips.sort_values(["sex", "total_bill"])
In [31]: tips
Out[31]:
total_bill tip sex smoker day time size
67 1.07 1.00 Female Yes Sat Dinner 1
92 3.75 1.00 Female Yes Fri Dinner 2
111 5.25 1.00 Female No Sat Dinner 1
145 6.35 1.50 Female No Thur Lunch 2
135 6.51 1.25 Female No Thur Lunch 2
.. ... ... ... ... ... ... ...
182 43.35 3.50 Male Yes Sun Dinner 3
156 46.17 5.00 Male No Sun Dinner 6
59 46.27 6.73 Male No Sat Dinner 4
212 46.33 9.00 Male No Sat Dinner 4
170 48.81 10.00 Male Yes Sat Dinner 3
[244 rows x 7 columns]
Обработка строк¶
Нахождение длины строки¶
В электронных таблицах количество символов в тексте можно узнать с помощью функции LEN. Ее можно использовать вместе с функцией TRIM, если нужно удалить лишние пробелы.
=LEN(TRIM(A2))
Вы можете узнать длину строки символов с помощью Series.str.len(). В Python 3 все строки являются строками Unicode. len включает конечные пробелы. Используйте len и rstrip, чтобы исключить пробелы в конце.
In [32]: tips["time"].str.len()
Out[32]:
67 6
92 6
111 6
145 5
135 5
..
182 6
156 6
59 6
212 6
170 6
Name: time, Length: 244, dtype: int64
In [33]: tips["time"].str.rstrip().str.len()
Out[33]:
67 6
92 6
111 6
145 5
135 5
..
182 6
156 6
59 6
212 6
170 6
Name: time, Length: 244, dtype: int64
Обратите внимание, что в этом случае множественные пробелы внутри строки останутся, так что функции эквивалентны не на 100%.
Поиск позиции подстроки¶
Функция электронной таблицы FIND возвращает позицию подстроки с первым символ 1.
В pandas вы можете найти положение символа в столбце строк с помощью метода Series.str.find(). find ищет первую позицию подстроки. Если подстрока найдена, метод возвращает ее позицию. Если не найдена, возвращается -1. Имейте в виду, что индексы Python отсчитываются от нуля.
In [34]: tips["sex"].str.find("ale")
Out[34]:
67 3
92 3
111 3
145 3
135 3
..
182 1
156 1
59 1
212 1
170 1
Name: sex, Length: 244, dtype: int64
Извлечение подстроки по позиции¶
В электронных таблицах есть формула MID для извлечения подстроки из заданной позиции. Чтобы получить первый символ:
=MID(A2,1,1)
В pandas вы можете использовать нотацию [] для извлечения подстроки из строки по местоположению. Имейте в виду, что индексы Python отсчитываются от нуля.
In [35]: tips["sex"].str[0:1]
Out[35]:
67 F
92 F
111 F
145 F
135 F
..
182 M
156 M
59 M
212 M
170 M
Name: sex, Length: 244, dtype: object
Извлечение n-ного слова¶
В Excel вы можете использовать Мастер преобразования текста в столбцы для разделения текста и извлечения определенного столбца. (Обратите внимание, что это можно сделать и с помощью формулы.)
Самый простой способ извлечь слова в pandas — разбить строки по пробелам, а затем сослаться на слово по индексу. Есть и более мощные подходы.
In [36]: firstlast = pd.DataFrame({"String": ["John Smith", "Jane Cook"]})
In [37]: firstlast["First_Name"] = firstlast["String"].str.split(" ", expand=True)[0]
In [38]: firstlast["Last_Name"] = firstlast["String"].str.rsplit(" ", expand=True)[1]
In [39]: firstlast
Out[39]:
String First_Name Last_Name
0 John Smith John Smith
1 Jane Cook Jane Cook
Изменение регистра¶
В электронных таблицах есть функции UPPER, LOWER и PROPER для преобразование текста в верхний, нижний и заглавный регистр соответственно.
Эквивалентные методы pandas: Series.str.upper(), Series.str.lower() и Series.str.title().
In [40]: firstlast = pd.DataFrame({"string": ["John Smith", "Jane Cook"]})
In [41]: firstlast["upper"] = firstlast["string"].str.upper()
In [42]: firstlast["lower"] = firstlast["string"].str.lower()
In [43]: firstlast["title"] = firstlast["string"].str.title()
In [44]: firstlast
Out[44]:
string upper lower title
0 John Smith JOHN SMITH john smith John Smith
1 Jane Cook JANE COOK jane cook Jane Cook
Объединение¶
В примерах объединения будут использоваться следующие таблицы:
In [45]: df1 = pd.DataFrame({"key": ["A", "B", "C", "D"], "value": np.random.randn(4)})
In [46]: df1
Out[46]:
key value
0 A 0.469112
1 B -0.282863
2 C -1.509059
3 D -1.135632
In [47]: df2 = pd.DataFrame({"key": ["B", "D", "D", "E"], "value": np.random.randn(4)})
In [48]: df2
Out[48]:
key value
0 B 1.212112
1 D -0.173215
2 D 0.119209
3 E -1.044236
В Excel объединение таблиц можно выполнить с помощью функции VLOOKUP.
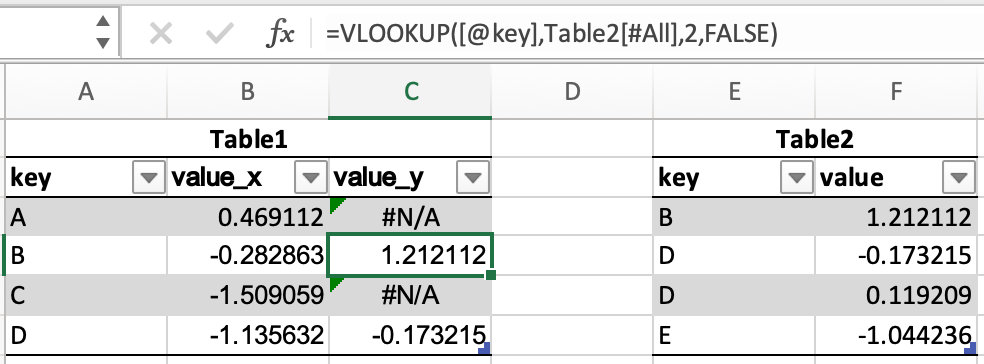
В pandas есть метод DataFrame.merge, который обеспечивает аналогичную функциональность. Данные не нужно сортировать заранее, а различные типы объединений выполняются с помощью ключевого слова how.
In [49]: inner_join = df1.merge(df2, on=["key"], how="inner")
In [50]: inner_join
Out[50]:
key value_x value_y
0 B -0.282863 1.212112
1 D -1.135632 -0.173215
2 D -1.135632 0.119209
In [51]: left_join = df1.merge(df2, on=["key"], how="left")
In [52]: left_join
Out[52]:
key value_x value_y
0 A 0.469112 NaN
1 B -0.282863 1.212112
2 C -1.509059 NaN
3 D -1.135632 -0.173215
4 D -1.135632 0.119209
In [53]: right_join = df1.merge(df2, on=["key"], how="right")
In [54]: right_join
Out[54]:
key value_x value_y
0 B -0.282863 1.212112
1 D -1.135632 -0.173215
2 D -1.135632 0.119209
3 E NaN -1.044236
In [55]: outer_join = df1.merge(df2, on=["key"], how="outer")
In [56]: outer_join
Out[56]:
key value_x value_y
0 A 0.469112 NaN
1 B -0.282863 1.212112
2 C -1.509059 NaN
3 D -1.135632 -0.173215
4 D -1.135632 0.119209
5 E NaN -1.044236
merge имеет ряд преимуществ перед VLOOKUP:
Искомое значение не обязательно должно быть в первом столбце таблицы поиска.
Если совпадают несколько строк, своя строка будет для каждого совпадения, а не только для первого.
Включаются все столбцы из таблицы поиска, а не только указанный столбец.
Поддерживаются более сложные операции объединения.
Другие соображения¶
Заполнение ячеек¶
Создайте ряд чисел по заданному шаблону в определенном наборе ячеек. В электронной таблице это можно сделать с помощью Shift + перетаскивания после ввода первого числа, или же путем ввода первых двух или трех значений с последующим перетаскиванием.
В pandas этого можно добиться, создав Series и назначив его нужным ячейкам.
In [57]: df = pd.DataFrame({"AAA": [1] * 8, "BBB": list(range(0, 8))})
In [58]: df
Out[58]:
AAA BBB
0 1 0
1 1 1
2 1 2
3 1 3
4 1 4
5 1 5
6 1 6
7 1 7
In [59]: series = list(range(1, 5))
In [60]: series
Out[60]: [1, 2, 3, 4]
In [61]: df.loc[2:5, "AAA"] = series
In [62]: df
Out[62]:
AAA BBB
0 1 0
1 1 1
2 1 2
3 2 3
4 3 4
5 4 5
6 1 6
7 1 7
Удаление дубликатов¶
Excel имеет встроенную функцию удаления повторяющихся значений. Аналогичный функционал поддерживается в pandas с drop_duplicates().
In [63]: df = pd.DataFrame(
....: {
....: "class": ["A", "A", "A", "B", "C", "D"],
....: "student_count": [42, 35, 42, 50, 47, 45],
....: "all_pass": ["Yes", "Yes", "Yes", "No", "No", "Yes"],
....: }
....: )
....:
In [64]: df.drop_duplicates()
Out[64]:
class student_count all_pass
0 A 42 Yes
1 A 35 Yes
3 B 50 No
4 C 47 No
5 D 45 Yes
In [65]: df.drop_duplicates(["class", "student_count"])
Out[65]:
class student_count all_pass
0 A 42 Yes
1 A 35 Yes
3 B 50 No
4 C 47 No
5 D 45 Yes
Сводные таблицы¶
Сводные таблицы из электронных таблиц могут быть реплицированы в pandas, см. изменение формы и сводные таблицы. Снова используя набор данных tips, давайте найдем среднее вознаграждение в зависимости от масштаба вечеринки и пола официанта.
В Excel мы используем следующую конфигурацию для сводной таблицы:
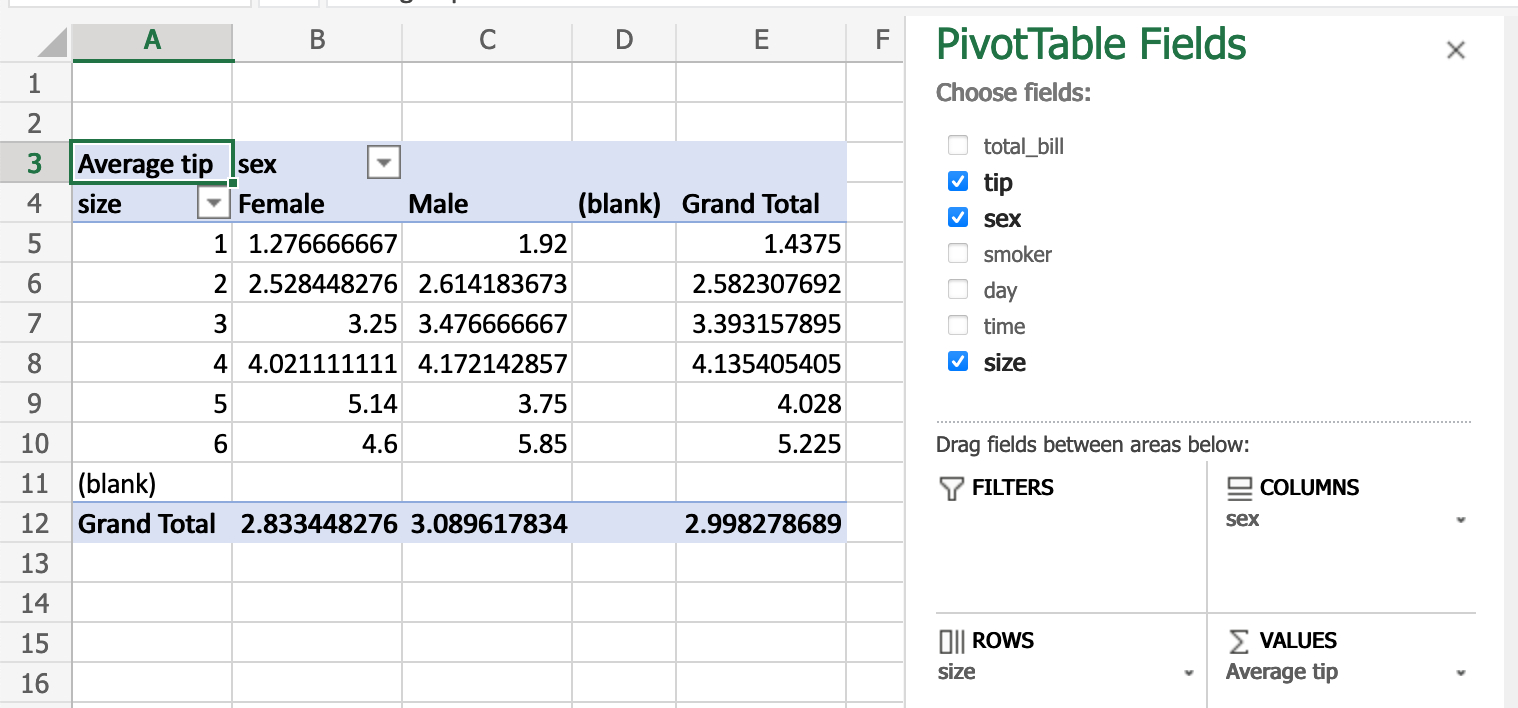
Эквивалент в pandas:
In [66]: pd.pivot_table(
....: tips, values="tip", index=["size"], columns=["sex"], aggfunc=np.average
....: )
....:
Out[66]:
sex Female Male
size
1 1.276667 1.920000
2 2.528448 2.614184
3 3.250000 3.476667
4 4.021111 4.172143
5 5.140000 3.750000
6 4.600000 5.850000
Добавление строки¶
Предполагая, что мы используем RangeIndex (с номером 0, 1 и т. д.), мы можем использовать concat(), чтобы добавить строку в конец DataFrame.
In [67]: df
Out[67]:
class student_count all_pass
0 A 42 Yes
1 A 35 Yes
2 A 42 Yes
3 B 50 No
4 C 47 No
5 D 45 Yes
In [68]: new_row = pd.DataFrame([["E", 51, True]],
....: columns=["class", "student_count", "all_pass"])
....:
In [69]: pd.concat([df, new_row])
Out[69]:
class student_count all_pass
0 A 42 Yes
1 A 35 Yes
2 A 42 Yes
3 B 50 No
4 C 47 No
5 D 45 Yes
0 E 51 True
Поиск и замена¶
Диалоговое окно поиска Excel показывает вам подходящие ячейки, одну за другой. В pandas эта операция обычно выполняется для всего столбца или DataFrame с помощью условных выражений.
In [70]: tips
Out[70]:
total_bill tip sex smoker day time size
67 1.07 1.00 Female Yes Sat Dinner 1
92 3.75 1.00 Female Yes Fri Dinner 2
111 5.25 1.00 Female No Sat Dinner 1
145 6.35 1.50 Female No Thur Lunch 2
135 6.51 1.25 Female No Thur Lunch 2
.. ... ... ... ... ... ... ...
182 43.35 3.50 Male Yes Sun Dinner 3
156 46.17 5.00 Male No Sun Dinner 6
59 46.27 6.73 Male No Sat Dinner 4
212 46.33 9.00 Male No Sat Dinner 4
170 48.81 10.00 Male Yes Sat Dinner 3
[244 rows x 7 columns]
In [71]: tips == "Sun"
Out[71]:
total_bill tip sex smoker day time size
67 False False False False False False False
92 False False False False False False False
111 False False False False False False False
145 False False False False False False False
135 False False False False False False False
.. ... ... ... ... ... ... ...
182 False False False False True False False
156 False False False False True False False
59 False False False False False False False
212 False False False False False False False
170 False False False False False False False
[244 rows x 7 columns]
In [72]: tips["day"].str.contains("S")
Out[72]:
67 True
92 False
111 True
145 False
135 False
...
182 True
156 True
59 True
212 True
170 True
Name: day, Length: 244, dtype: bool
Метод replace() в pandas сопоставим с Replace All в Excel.
In [73]: tips.replace("Thu", "Thursday")
Out[73]:
total_bill tip sex smoker day time size
67 1.07 1.00 Female Yes Sat Dinner 1
92 3.75 1.00 Female Yes Fri Dinner 2
111 5.25 1.00 Female No Sat Dinner 1
145 6.35 1.50 Female No Thur Lunch 2
135 6.51 1.25 Female No Thur Lunch 2
.. ... ... ... ... ... ... ...
182 43.35 3.50 Male Yes Sun Dinner 3
156 46.17 5.00 Male No Sun Dinner 6
59 46.27 6.73 Male No Sat Dinner 4
212 46.33 9.00 Male No Sat Dinner 4
170 48.81 10.00 Male Yes Sat Dinner 3
[244 rows x 7 columns]