Как легко обрабатывать данные временных рядов?¶
In [1]: import pandas as pd
In [2]: import matplotlib.pyplot as plt
-
Данные о качестве воздуха
В этом руководстве используются данные о концентрации \(NO_2\), предоставленные openaq и использующие пакет py-openaq. Набор данных
Исходные данныеair_quality_no2_long.csvсодержит значения \(NO_2\) от измерительных станций FR04014, BETR801 и London Westminster в Париже, Антверпене и Лондоне соответственно.In [3]: air_quality = pd.read_csv("data/air_quality_no2_long.csv") In [4]: air_quality = air_quality.rename(columns={"date.utc": "datetime"}) In [5]: air_quality.head() Out[5]: city country datetime location parameter value unit 0 Paris FR 2019-06-21 00:00:00+00:00 FR04014 no2 20.0 µg/m³ 1 Paris FR 2019-06-20 23:00:00+00:00 FR04014 no2 21.8 µg/m³ 2 Paris FR 2019-06-20 22:00:00+00:00 FR04014 no2 26.5 µg/m³ 3 Paris FR 2019-06-20 21:00:00+00:00 FR04014 no2 24.9 µg/m³ 4 Paris FR 2019-06-20 20:00:00+00:00 FR04014 no2 21.4 µg/m³
In [6]: air_quality.city.unique() Out[6]: array(['Paris', 'Antwerpen', 'London'], dtype=object)
Использование свойств даты и времени pandas¶
Я хочу работать с датами в столбце
datetimeкак с объектами даты и времени, а не как с обычным текстом.In [7]: air_quality["datetime"] = pd.to_datetime(air_quality["datetime"]) In [8]: air_quality["datetime"] Out[8]: 0 2019-06-21 00:00:00+00:00 1 2019-06-20 23:00:00+00:00 2 2019-06-20 22:00:00+00:00 3 2019-06-20 21:00:00+00:00 4 2019-06-20 20:00:00+00:00 ... 2063 2019-05-07 06:00:00+00:00 2064 2019-05-07 04:00:00+00:00 2065 2019-05-07 03:00:00+00:00 2066 2019-05-07 02:00:00+00:00 2067 2019-05-07 01:00:00+00:00 Name: datetime, Length: 2068, dtype: datetime64[ns, UTC]
Первоначально значения в
datetimeпредставляют собой строки символов и не обеспечивают никаких операций с датой и временем (например, извлечение года, дня недели и так далее). Применяя функциюto_datetime, pandas интерпретирует строки и преобразует их в объекты даты и времени (то естьdatetime64[ns, UTC]). Эти объекты даты и времени, похожие наdatetime.datetimeв Python, в pandas мы называемpandas.Timestamp.
Примечание
Поскольку многие наборы данных содержат информацию о дате и времени в одном из столбцов, функции ввода pandas, такие как pandas.read_csv() и pandas.read_json(), могут выполнять преобразование в даты при чтении данных. Для этого используется parse_dates и список столбцов, которые следует читать как Timestamp:
pd.read_csv("../data/air_quality_no2_long.csv", parse_dates=["datetime"])
Чем полезны объекты pandas.Timestamp? Давайте проиллюстрируем добавленную ценность несколькими примерами.
Какова начальная и конечная дата набора данных временного ряда, с которым мы работаем?
In [9]: air_quality["datetime"].min(), air_quality["datetime"].max()
Out[9]:
(Timestamp('2019-05-07 01:00:00+0000', tz='UTC'),
Timestamp('2019-06-21 00:00:00+0000', tz='UTC'))
Использование pandas.Timestamp для даты и времени позволяет выполнять вычисления с информацией о дате и делать их сопоставимыми. Следовательно, можно использовать это, чтобы получить длину нашего временного ряда:
In [10]: air_quality["datetime"].max() - air_quality["datetime"].min()
Out[10]: Timedelta('44 days 23:00:00')
Результатом является объект pandas.Timedelta, аналогичный datetime.timedelta из стандартной библиотеки Python и определяющий продолжительность времени.
Различные концепции времени, поддерживаемые pandas, объясняются в разделе руководства пользователя о концепциях, связанных со временем.
Я хочу добавить в
DataFrameновый столбец, содержащий только месяц.In [11]: air_quality["month"] = air_quality["datetime"].dt.month In [12]: air_quality.head() Out[12]: city country datetime location parameter value unit month 0 Paris FR 2019-06-21 00:00:00+00:00 FR04014 no2 20.0 µg/m³ 6 1 Paris FR 2019-06-20 23:00:00+00:00 FR04014 no2 21.8 µg/m³ 6 2 Paris FR 2019-06-20 22:00:00+00:00 FR04014 no2 26.5 µg/m³ 6 3 Paris FR 2019-06-20 21:00:00+00:00 FR04014 no2 24.9 µg/m³ 6 4 Paris FR 2019-06-20 20:00:00+00:00 FR04014 no2 21.4 µg/m³ 6
Используя объекты
Timestampдля дат, pandas предоставляет множество свойств, связанных со временем. Например,month, а ещеyear,weekofyear,quarterи так далее. Все эти свойства доступны через метод доступаdt.
Обзор существующих свойств даты приведен в таблице обзора компонентов времени и даты. Более подробно о методе доступа dt для возврата свойств, подобных дате и времени, объясняется в специальном разделе, посвященном методу доступа dt.
Какова средняя концентрация \(NO_2\) в каждый день недели в каждой точке измерения?
In [13]: air_quality.groupby( ....: [air_quality["datetime"].dt.weekday, "location"])["value"].mean() ....: Out[13]: datetime location 0 BETR801 27.875000 FR04014 24.856250 London Westminster 23.969697 1 BETR801 22.214286 FR04014 30.999359 ... 5 FR04014 25.266154 London Westminster 24.977612 6 BETR801 21.896552 FR04014 23.274306 London Westminster 24.859155 Name: value, Length: 21, dtype: float64
Помните подход «разделить-применить-объединить» из урока по сводной статистике? Здесь мы хотим рассчитать заданную статистику (например, среднее \(NO_2\)) для каждого дня недели и для каждой точки измерения. Для группировки по дням недели, мы используем свойство даты и времени
weekday(с Monday=0 и Sunday=6) объектаTimestamp, которое также доступно с помощью метода доступаdt. Группировка по местоположению и дням недели может быть выполнена, чтобы разделить расчет среднего значения для каждой из этих комбинаций.Опасно
Поскольку в этих примерах мы работаем с очень короткими временными рядами, анализ не дает долгосрочного репрезентативного результата!
Начертить диаграмму \(NO_2\) в течение дня для нашего временного ряда со всех станций вместе. Другими словами, каково среднее значение для каждого часа дня?
In [14]: fig, axs = plt.subplots(figsize=(12, 4)) In [15]: air_quality.groupby(air_quality["datetime"].dt.hour)["value"].mean().plot( ....: kind='bar', rot=0, ax=axs ....: ) ....: Out[15]: <AxesSubplot:xlabel='datetime'> In [16]: plt.xlabel("Hour of the day"); # custom x label using matplotlib In [17]: plt.ylabel("$NO_2 (µg/m^3)$");
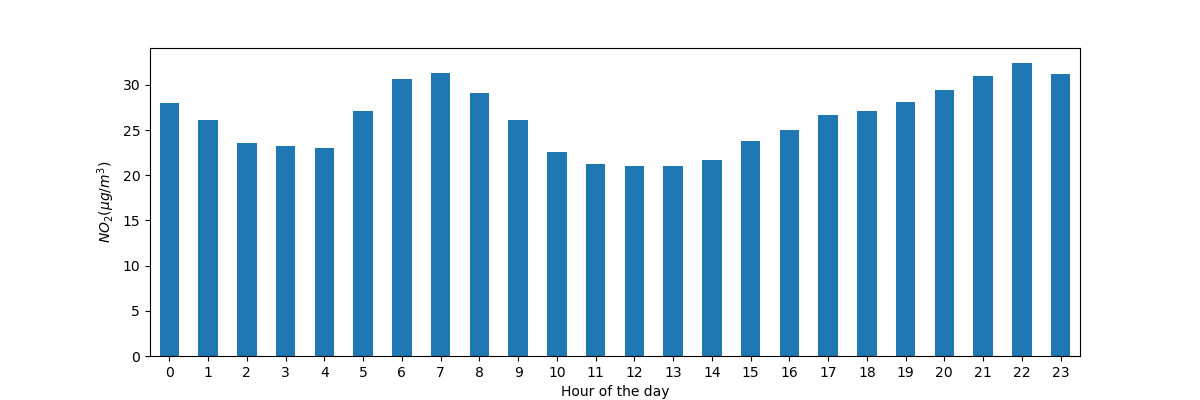
Как и в предыдущем случае, мы хотим рассчитать заданную статистику (например, среднее значение \(NO_2\)) для каждого часа дня, и снова можем использовать подход «разделить-применить-объединить». В этом случае мы используем свойство datetime
hourобъектаTimestamp, которое также доступно с помощью метода доступаdt.
Дата и время как индекс¶
В уроке по изменению структуры таблиц мы показали, как использовать pivot() для изменения формы таблицы, чтобы для каждого из местоположений был отдельный столбец:
In [18]: no_2 = air_quality.pivot(index="datetime", columns="location", values="value")
In [19]: no_2.head()
Out[19]:
location BETR801 FR04014 London Westminster
datetime
2019-05-07 01:00:00+00:00 50.5 25.0 23.0
2019-05-07 02:00:00+00:00 45.0 27.7 19.0
2019-05-07 03:00:00+00:00 NaN 50.4 19.0
2019-05-07 04:00:00+00:00 NaN 61.9 16.0
2019-05-07 05:00:00+00:00 NaN 72.4 NaN
Примечание
При повороте данных информация о дате и времени стала индексом таблицы. Обычно установить столбец в качестве индекса можно с помощью функции set_index.
Работа с индексом, в качестве которого выступают дата и время (например, DatetimeIndex), обеспечивает мощные возможности. Например, можно не использовать метод доступа dt для получения свойств временных рядов, поскольку эти свойства доступны непосредственно в индексе:
In [20]: no_2.index.year, no_2.index.weekday
Out[20]:
(Int64Index([2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019,
...
2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019],
dtype='int64', name='datetime', length=1033),
Int64Index([1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
...
3, 3, 3, 3, 3, 3, 3, 3, 3, 4],
dtype='int64', name='datetime', length=1033))
К другим преимуществам относятся удобная установка временного интервала или адаптированная шкала времени на графиках. Давайте применим это к нашим данным.
Создать график значений \(NO_2\) на разных станциях с 20 мая до 21 мая включительно.
In [21]: no_2["2019-05-20":"2019-05-21"].plot();
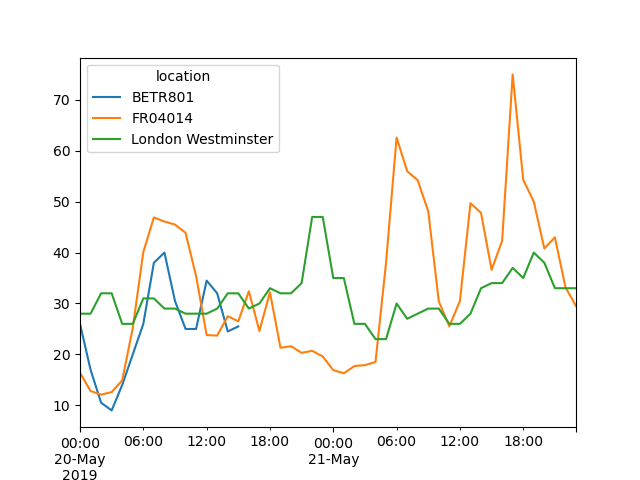
Предоставляя строку для преобразования в дату и время, можно выбрать конкретное подмножество данных в
DatetimeIndex.
Более подробная информация о DatetimeIndex и срезах с использованием строк представлена в разделе об индексировании временных рядов.
Дискретизация временного ряда на другую частоту¶
Агрегировать текущие почасовые значения временных рядов до месячного максимального значения на каждой из станций.
In [22]: monthly_max = no_2.resample("M").max() In [23]: monthly_max Out[23]: location BETR801 FR04014 London Westminster datetime 2019-05-31 00:00:00+00:00 74.5 97.0 97.0 2019-06-30 00:00:00+00:00 52.5 84.7 52.0
Очень мощным методом для данных временных рядов с индексом в виде даты и времени является возможность преобразования временных рядов в другую частоту (например, преобразование секундных данных в 5-минутные данные).
Метод resample() похож на операцию groupby:
Метод обеспечивает группировку по времени с помощью строки, которая определяет целевую частоту (например,
M,5Hи так далее).Методу требуется функция агрегирования, такая как
meanилиmax.
Обзор псевдонимов, используемых для определения частоты временных рядов, приведен в таблице обзора псевдонимов смещения.
Частота временного ряда, когда она задана, предоставляется атрибутом freq:
In [24]: monthly_max.index.freq
Out[24]: <MonthEnd>
Построить график среднесуточного значения \(NO_2\) на каждой из станций.
In [25]: no_2.resample("D").mean().plot(style="-o", figsize=(10, 5));
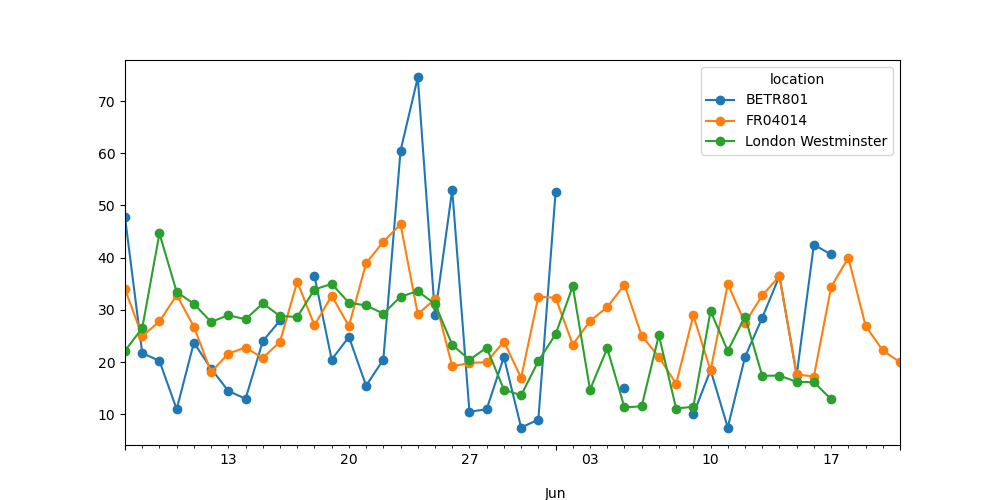
Более подробная информация о возможностях применения resampling к временным рядам представлена в руководстве пользователя.
ЗАПОМНИТЕ
Валидные строки с датой могут быть преобразованы в объекты даты и времени с помощью функции
to_datetimeили как часть функций чтения.Объекты даты и времени в pandas поддерживают вычисления, логические операции и удобные свойства, связанные с датой, с помощью метода доступа
dt.DatetimeIndexсодержит эти свойства, связанные с датой, и поддерживает срезы.Resample— это мощный метод изменения частоты временного ряда.
Полный обзор временных рядов приведен на страницах руководства пользователя о функциональных возможностях использования временных рядов и дат.