Как изменять структуру таблиц?¶
In [1]: import pandas as pd
- Данные о Титанике
В этом руководстве используется набор данных Titanic, сохраненный в формате CSV. Данные состоят из следующих столбцов данных:
PassengerId: Идентификатор каждого пассажира.
Survived: Имеет значения 0 и 1. 0 для не выживших и 1 для выживших.
Pclass: Существует 3 класса: класс 1, класс 2 и класс 3.
Name: Имя пассажира.
Sex: Пол пассажира.
Age: Возраст пассажира.
SibSp: Указание на то, что у пассажира есть братья, сестры и супруг.
Parch: Пассажир один или с семьей.
Ticket: Номер билета пассажира.
Fare: Указание тарифа.
Cabin: Каюта пассажира.
Embarked: Категория причала.
In [2]: titanic = pd.read_csv("data/titanic.csv") In [3]: titanic.head() Out[3]: PassengerId Survived Pclass ... Fare Cabin Embarked 0 1 0 3 ... 7.2500 NaN S 1 2 1 1 ... 71.2833 C85 C 2 3 1 3 ... 7.9250 NaN S 3 4 1 1 ... 53.1000 C123 S 4 5 0 3 ... 8.0500 NaN S [5 rows x 12 columns]
-
Данные о качестве воздуха
В этом руководстве используются данные о концентрации \(NO_2\) в воздухе и о твердых частицах размером менее 2,5 микрометров, предоставленные openaq и использующие пакет py-openaq. Набор данных
air_quality_long.csvсодержит значения \(NO_2\) и \(PM_{25}\) от измерительных станций FR04014, BETR801 и London Westminster в Париже, Антверпене и Лондоне соответственно.Набор данных о качестве воздуха включает следующие столбцы:
city: город, в котором расположен датчик (Париж, Антверпен или Лондон).
country: страна, в которой используется датчик (FR, BE или GB).
location: идентификатор датчика (FR04014, BETR801 или London Westminster).
parameter: параметр, измеряемый датчиком (\(NO_2\) либо твердые частицы).
value: измеренное значение.
unit: единица измерения параметра, в данном случае «мкг/м³».
В качестве индекса в этом DataFrame выступает
datetime, то есть дата и время измерения.Исходные данныеПримечание
Данные о качестве воздуха предоставлены в так называемом длинном формате, где каждое наблюдение находится в отдельной строке, а каждая переменная — в отдельном столбце таблицы данных. Длинный (или узкий) формат также известен как формат аккуратных данных.
In [4]: air_quality = pd.read_csv( ...: "data/air_quality_long.csv", index_col="date.utc", parse_dates=True ...: ) ...: In [5]: air_quality.head() Out[5]: city country location parameter value unit date.utc 2019-06-18 06:00:00+00:00 Antwerpen BE BETR801 pm25 18.0 µg/m³ 2019-06-17 08:00:00+00:00 Antwerpen BE BETR801 pm25 6.5 µg/m³ 2019-06-17 07:00:00+00:00 Antwerpen BE BETR801 pm25 18.5 µg/m³ 2019-06-17 06:00:00+00:00 Antwerpen BE BETR801 pm25 16.0 µg/m³ 2019-06-17 05:00:00+00:00 Antwerpen BE BETR801 pm25 7.5 µg/m³
Сортировка строк таблицы¶
Я хочу отсортировать данные Титаника по возрасту пассажиров.
In [6]: titanic.sort_values(by="Age").head() Out[6]: PassengerId Survived Pclass Name Sex ... Parch Ticket Fare Cabin Embarked 803 804 1 3 Thomas, Master. Assad Alexander male ... 1 2625 8.5167 NaN C 755 756 1 2 Hamalainen, Master. Viljo male ... 1 250649 14.5000 NaN S 644 645 1 3 Baclini, Miss. Eugenie female ... 1 2666 19.2583 NaN C 469 470 1 3 Baclini, Miss. Helene Barbara female ... 1 2666 19.2583 NaN C 78 79 1 2 Caldwell, Master. Alden Gates male ... 2 248738 29.0000 NaN S [5 rows x 12 columns]
Я хочу отсортировать данные Титаника по классу салона и возрасту в порядке убывания.
In [7]: titanic.sort_values(by=['Pclass', 'Age'], ascending=False).head() Out[7]: PassengerId Survived Pclass Name Sex ... Parch Ticket Fare Cabin Embarked 851 852 0 3 Svensson, Mr. Johan male ... 0 347060 7.7750 NaN S 116 117 0 3 Connors, Mr. Patrick male ... 0 370369 7.7500 NaN Q 280 281 0 3 Duane, Mr. Frank male ... 0 336439 7.7500 NaN Q 483 484 1 3 Turkula, Mrs. (Hedwig) female ... 0 4134 9.5875 NaN S 326 327 0 3 Nysveen, Mr. Johan Hansen male ... 0 345364 6.2375 NaN S [5 rows x 12 columns]
С помощью
DataFrame.sort_values()строки в таблице сортируются в соответствии с определенными столбцами. Индекс будет следовать порядку строк.
Более подробная информация о сортировке таблиц приведена в разделе руководства пользователя о сортировке данных.
Из длинного в широкий формат¶
Давайте воспользуемся небольшим подмножеством набора данных о качестве воздуха. Сфокусируемся на данных о \(NO_2\) и используем только первые два измерения с каждой станции (location), то есть заголовочные строки (.head()) каждой группы. Подмножество данных будет называться no2_subset.
# filter for no2 data only
In [8]: no2 = air_quality[air_quality["parameter"] == "no2"]
# use 2 measurements (head) for each location (groupby)
In [9]: no2_subset = no2.sort_index().groupby(["location"]).head(2)
In [10]: no2_subset
Out[10]:
city country location parameter value unit
date.utc
2019-04-09 01:00:00+00:00 Antwerpen BE BETR801 no2 22.5 µg/m³
2019-04-09 01:00:00+00:00 Paris FR FR04014 no2 24.4 µg/m³
2019-04-09 02:00:00+00:00 London GB London Westminster no2 67.0 µg/m³
2019-04-09 02:00:00+00:00 Antwerpen BE BETR801 no2 53.5 µg/m³
2019-04-09 02:00:00+00:00 Paris FR FR04014 no2 27.4 µg/m³
2019-04-09 03:00:00+00:00 London GB London Westminster no2 67.0 µg/m³

Мне нужны значения для трех станций в виде отдельных столбцов рядом друг с другом.
In [11]: no2_subset.pivot(columns="location", values="value") Out[11]: location BETR801 FR04014 London Westminster date.utc 2019-04-09 01:00:00+00:00 22.5 24.4 NaN 2019-04-09 02:00:00+00:00 53.5 27.4 67.0 2019-04-09 03:00:00+00:00 NaN NaN 67.0
Функция
pivot()предназначена исключительно для изменения формы данных: требуется одно значение для каждой комбинации индекса и столбца.
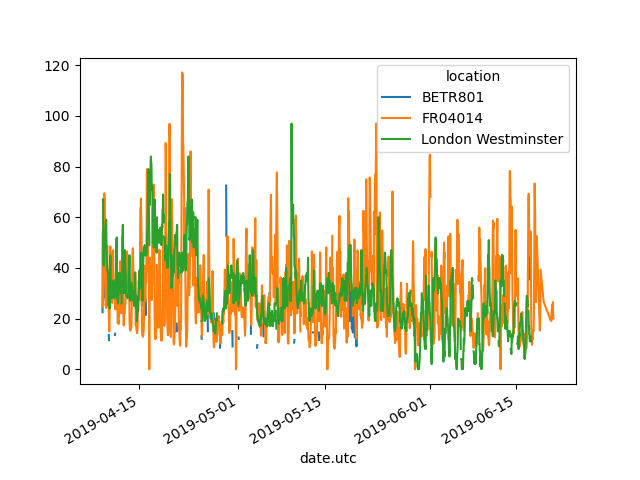
Поскольку pandas поддерживает построение диаграмм из нескольких столбцов (см. урок по построению диаграмм) «из коробки», преобразование из длинного в широкий формат таблицы позволяет отображать разные временные ряды одновременно:
In [12]: no2.head()
Out[12]:
city country location parameter value unit
date.utc
2019-06-21 00:00:00+00:00 Paris FR FR04014 no2 20.0 µg/m³
2019-06-20 23:00:00+00:00 Paris FR FR04014 no2 21.8 µg/m³
2019-06-20 22:00:00+00:00 Paris FR FR04014 no2 26.5 µg/m³
2019-06-20 21:00:00+00:00 Paris FR FR04014 no2 24.9 µg/m³
2019-06-20 20:00:00+00:00 Paris FR FR04014 no2 21.4 µg/m³
In [13]: no2.pivot(columns="location", values="value").plot()
Out[13]: <AxesSubplot:xlabel='date.utc'>
Примечание
Когда параметр index не определен, используется существующий индекс (метки строк).
Дополнительные сведения о pivot() см. в разделе руководства пользователя, посвященном повороту объектов DataFrame.
Сводная таблица¶

Мне нужны средние концентрации \(NO_2\) и \(PM_{2.5}\) на каждой из станций в виде таблицы.
In [14]: air_quality.pivot_table( ....: values="value", index="location", columns="parameter", aggfunc="mean" ....: ) ....: Out[14]: parameter no2 pm25 location BETR801 26.950920 23.169492 FR04014 29.374284 NaN London Westminster 29.740050 13.443568
В случае
pivot()данные только переупорядочиваются. Когда же необходимо объединить несколько значений (в нашем случае это значения на разных временных интервалах), можно использоватьpivot_table(), указывая агрегирующую функцию (например, среднее) для объединения значений.
Сводные таблицы хорошо известны тем, кто работает с электронными таблицами. Если вам нужны сводные столбцы для каждой группы, установите для параметра margins значение True:
In [15]: air_quality.pivot_table(
....: values="value",
....: index="location",
....: columns="parameter",
....: aggfunc="mean",
....: margins=True,
....: )
....:
Out[15]:
parameter no2 pm25 All
location
BETR801 26.950920 23.169492 24.982353
FR04014 29.374284 NaN 29.374284
London Westminster 29.740050 13.443568 21.491708
All 29.430316 14.386849 24.222743
Дополнительные сведения о pivot_table() см. в разделе руководства пользователя о сводных таблицах.
Примечание
Если вам интересно, pivot_table() действительно напрямую связан с groupby(). Тот же результат можно получить, группируя как по parameter, так и по location:
air_quality.groupby(["parameter", "location"]).mean()
Подробнее о сочетании groupby() и unstack() читайте в соответствующем разделе руководства пользователя.
Из широкого в длинный формат¶
Начинем заново с широкоформатной таблицы, созданной в предыдущем разделе:
In [16]: no2_pivoted = no2.pivot(columns="location", values="value").reset_index()
In [17]: no2_pivoted.head()
Out[17]:
location date.utc BETR801 FR04014 London Westminster
0 2019-04-09 01:00:00+00:00 22.5 24.4 NaN
1 2019-04-09 02:00:00+00:00 53.5 27.4 67.0
2 2019-04-09 03:00:00+00:00 54.5 34.2 67.0
3 2019-04-09 04:00:00+00:00 34.5 48.5 41.0
4 2019-04-09 05:00:00+00:00 46.5 59.5 41.0

Я хочу собрать все измерения качества воздуха \(NO_2\) в один столбец (длинный формат).
In [18]: no_2 = no2_pivoted.melt(id_vars="date.utc") In [19]: no_2.head() Out[19]: date.utc location value 0 2019-04-09 01:00:00+00:00 BETR801 22.5 1 2019-04-09 02:00:00+00:00 BETR801 53.5 2 2019-04-09 03:00:00+00:00 BETR801 54.5 3 2019-04-09 04:00:00+00:00 BETR801 34.5 4 2019-04-09 05:00:00+00:00 BETR801 46.5
Метод
pandas.melt()вDataFrameпреобразует таблицу данных из широкого формата в длинный. Заголовки столбцов становятся именами переменных во вновь созданном столбце.
Приведенное решение — это краткая версия применения pandas.melt(). Метод разберет все столбцы, НЕ упомянутые в id_vars, на два столбца: столбец с именами заголовков исходных столбцов и столбец с собственно значениями. Последний столбец по умолчанию получает имя value.
Метод pandas.melt() можно определить более подробно:
In [20]: no_2 = no2_pivoted.melt(
....: id_vars="date.utc",
....: value_vars=["BETR801", "FR04014", "London Westminster"],
....: value_name="NO_2",
....: var_name="id_location",
....: )
....:
In [21]: no_2.head()
Out[21]:
date.utc id_location NO_2
0 2019-04-09 01:00:00+00:00 BETR801 22.5
1 2019-04-09 02:00:00+00:00 BETR801 53.5
2 2019-04-09 03:00:00+00:00 BETR801 54.5
3 2019-04-09 04:00:00+00:00 BETR801 34.5
4 2019-04-09 05:00:00+00:00 BETR801 46.5
Результат тот же, но определен более подробно:
value_varsявно определяет, какие столбцы нужно преобразовать в длинную таблицу.value_nameпозволяет задать имя для столбца значений вместо используемого по умолчанию имениvalue.var_nameпозволяет задать имя для столбца, в котором собраны имена заголовков исходных столбцов. В противном случае он принимает имя индекса или переменную по умолчанию.
Следовательно, аргументы value_name и var_name — это просто определяемые пользователем имена для двух сгенерированных столбцов. В id_vars и value_vars определяются столбцы для преобразования в длинный формат.
Преобразование из широкого формата в длинный с помощью pandas.melt() объясняется в разделе руководства пользователя об изменении формата с помощью функции melt.
ЗАПОМНИТЕ
Сортировка по одному или нескольким столбцам поддерживается параметром
sort_values.Функция
pivotпредназначена исключительно для реструктурирования данных,pivot_tableподдерживает агрегирование.Обратной функцией к
pivot(из длинного в широкий формат) являетсяmelt(из широкого в длинный формат).
Полный обзор доступен в руководстве пользователя на страницах об изменении формы и поворотах таблиц.